2024 우수잡지


-MPLAB Software Updates-KR 466x58H.jpg)


인텔, 새로운 아키텍처 및 기술로 시장 확대 기회 추구

10나노미터 기반 PC, 데이터센터 및 네트워킹 시스템, AI 및 암호화 가속 지원하는 차세대 ‘서니코브’(‘Sunny Cove’) 아키텍처, 업계 최초의 3D 로직 칩 패키징 기술 선보여

인텔 ‘아키텍처 데이(Architecture Day)’에서 경영진, 기술연구진 및 관련 담당자들은 차세대 기술을 공개하고 데이터 집약적인 워크로드 분야의 확대를 지원하기 위한 전략의 진척 상황을 공유했다. 이러한 워크로드에는 PC 및 스마트 디바이스들, 초고속 네트워크, 유비쿼터스 인공지능, 전문화된 클라우드 데이터센터와 자율주행차 등이 포함된다.
인텔은 PC, 데이터센터 및 네트워킹용으로 개발 중인 다양한 종류의 10나노미터(nm) 기반 시스템을 시연했으며, 확장된 영역의 워크로드를 겨냥한 다른 기술들도 선보였다.
더 알아보기: 인텔, 새로운 아키텍처 및 기술로 시장 확대 기회 추구
인텔은 또한 기술과 사용자 경험에서의 약진을 이루기 위해 상당한 투자 및 혁신이 추진되고 있는 6개의 엔지니어링 분야에 초점을 맞춘 기술 전략을 공유했다. 6개의 분야는 첨단 제조 프로세스 및 패키징, AI와 그래픽 등 전문화된 작업의 속도 향상을 위한 새로운 아키텍처, 초고속 메모리 기술, 인터커넥트, 임베디드 보안 기능, 인텔의 컴퓨트 로드맵간 개발자용 프로그래밍을 통합하고 단순화하는 공통 소프트웨어이다.
이러한 기술들은 2022년까지1 3000억 달러 규모를 넘어설 것으로 예상되는 시장에서 한층 다양해질 컴퓨팅 시대를 위한 토대를 마련할 것이다.
인텔 아키텍처 데이의 주요 내용은 다음과 같다.
업계 최초의 로직 칩 3D 스택킹: 인텔은 로직-온-로직(logic-on-logic) 통합이 가능하도록 사상 최초로 3D 스태킹의 이점을 적용한 새로운 3D 패키징 기술인 ‘포베로스(Foveros)’를 선보였다.
포베로스는 고성능, 고밀도 및 저전력 실리콘 프로세스 기술을 결합할 디바이스 및 시스템을 준비한다. 포베로스는 처음으로 다이 스태킹(die stacking)을 기존의 수동 인터포저 및 스택 메모리를 넘어, CPU, 그래픽 및 AI 프로세서 등 고성능 로직으로까지 확대시킬 것으로 기대된다.
설계자들이 새로운 디바이스 폼팩터에서 다양한 메모리 및 I/O 요소에 IP블록을 ‘믹스 앤 매치’할 기술을 찾으면서, 인텔의 이러한 기술은 상당한 유연성을 제공한다. 이 기술은 제품을 소형화된 ‘칩렛(chiplet)’으로 세분화할 수 있다. 칩렛은 I/O, SRAM 및 전원 공급 회로가 베이스 다이(base die)에 기본 장착되어 있고 그 위에 고성능 로직 칩렛이 올라간다.
인텔은 2019년 하반기부터 포베로스를 활용한 다양한 제품을 출시할 예정이다. 첫 포베로스 제품은 저전력 22FFL 베이스 다이가 적용된 고성능 10 나노미터 연산 스택 칩렛이다. 이를 통해 소형 폼 팩터에서도 최고의 성능과 전력 효율성의 결합이 가능해질 것이다.
포베로스는 2018년 도입된 인텔의 획기적인 EMIB(Embedded Multi-die Interconnect Bridge) 2D 패키징 기술의 뒤를 잇는다.
새로운 서니코브(Sunny Cove) CPU 아키텍처: 인텔은 차세대 CPU 마이크로아키텍처인 서니 코브(Sunny Cove)를 선보였다. 서니코브는 범용 연산 작업에서 클럭 당 성능 및 전력 효율성의 향상을 위해 설계되었고, 인공지능 및 암호화처럼 특별한 목적의 연산 작업을 가속화하는 새로운 기능이 포함되어 있다. 서니 코브는 내년 말 인텔의 차세대 서버(Intel® Xeon®) 및 클라이언트(Intel® Core™) 프로세서의 기반이 될 제품으로, 주요 특징은 다음과 같다.
- 더 많은 연산을 병렬로 실행할 수 있도록 강화된 마이크로아키텍처
- 지연을 줄이기 위한 새로운 알고리즘
- 데이터 중심 워크로드를 최적화할 수 있도록 키 버퍼(key buffer) 및 캐시 크기 확대
- 특정 활용사례(use case) 및 알고리즘을 위한 확장. 예로, 벡터 AES 및 SHA-NI 등 암호화를 위한 새로운 성능 강화 방법 및 압축/압축 해제 등 기타 중요 용도
서니코브는 지연 감소 및 처리량 확대가 가능할 뿐만 아니라 병렬 처리도 대폭 확대해 게이밍부터 미디어는 물론 데이터중심 애플리케이션까지 다양한 경험을 개선할 것으로 전망되고 있다.
차세대 그래픽: 인텔은 이전의 인텔 Gen9 그래픽(24개 EU)보다 두 배 이상 늘어난 64개의 강화된 실행 유닛을 갖춘 새로운 Gen11 내장 그래픽을 선보이면서 1 TFLOPS의 벽을 허물고자 한다. 새로운 내장 그래픽은 2019년부터 10나노미터 기반 프로세서에 탑재될 예정이다.
새로운 내장 그래픽 아키텍처는 인텔 Gen9 그래픽과 비교해 클럭 당 연산 성능을 2배 향상시킬 것으로 예상된다. 1 TFLOPS 성능을 넘어서는 해당 아키텍처는 게임 플레이 성능을 강화하도록 설계되었다. Gen11 그래픽은 사진 인식처럼 일부 가장 대중적인 추론 애플리케이션에서 두 배의 AI 성능을 제공할 것으로 기대되고 있다. Gen11 그래픽은 또한 향상된 미디어 인코더 및 디코더 기능을 지원해 전력 공급이 제한적인 상황에서도 4K 동영상 스트림과 8K 콘텐츠 제작을 지원할 것으로 기대된다. 뿐만 아니라 Gen11은 인텔® 어댑티브 싱크(Intel® Adaptive Sync) 기술을 지원해 게이밍을 위한 매끄러운 프레임 레이트를 제공한다.
인텔은 또한 2020년까지 외장 그래픽 프로세서를 도입할 계획임을 재확인했다.
‘One API’ 소프트웨어: 인텔은 CPU, GPU, FPGA, AI 및 기타 가속기(accelerator) 등 다양한 컴퓨팅 엔진에서의 프로그래밍을 단순화하기 위한 ‘One API’ 프로젝트를 발표했다. 해당 프로젝트에는 코드의 가속화를 최대로 이끌어낼 수 있도록 소프트웨어에서 하드웨어로 매핑된 개발자용 툴을 포괄적으로 포함 및 통합한 포트폴리오가 포함되어 있다. 프로젝트 공개 시점은 2019년이 될 것으로 예상된다.
메모리 및 스토리지: 인텔은 인텔® 옵테인™(Intel® Optane™ ) 기술 및 해당 기술 기반 제품에 대한 새로운 소식을 공개했다. 인텔 옵테인™ DC 퍼시스턴트 메모리(Intel® Optane™ DC persistent memory)는 메모리와 같은 성능을 데이터 지속과 대용량 스토리지와 융합하는 신규 제품이다. 이러한 혁신적인 기술은 AI 및 대규모 데이터베이스 등에 사용되는 한층 큰 규모의 데이터셋을 더욱 빠르게 처리할 수 있도록 더 많은 데이터를 CPU에 가깝게 가져온다. 해당 메모리의 대규모 용량과 데이터 지속은 스토리지에 오가야 할 필요를 줄여 워크로드 성능을 개선시킬 수 있다. 인텔 옵테인 DC 퍼시스턴트 메모리는 CPU에 캐시 라인(64B) 읽기를 전달한다. 요청한 데이터가 디램(DRAM)에 있지 않거나, 애플리케이션이 읽기 작업을 옵테인 퍼시스턴트 메모리로 보낸 경우 옵테인 퍼시스턴트 메모리 장착 시 평균 유휴 읽기 지연 시간(average idle read latency)은 약 350 나노세컨일 것으로 예상된다. 확장 시, 한 개의 옵테인 DC SSD에서 평균 유휴 읽기 지연 시간은 1만 나노세컨(10 마이크로세컨드)으로 상당한 개선을 보인다2. CPU의 기억 제어기에 캐시되어 있거나 애플리케이션에 의해 다이렉트되는 등, 요청받은 데이터가 DRAM에 있는 경우 메모리 서브시스템의 반응 속도는 100 나노세컨 이하로 DRAM과 동일할 것으로 예상된다.
인텔은 또한 인텔의 1테라비트 QLC NAND 다이에 기반한 SSD가 어떻게 더 많은 데이터를 HDD에서 SSD로 옮겨, 해당 데이터에 대한 한층 빠른 접근을 가능하게 하는지를 시연을 선보였다.
인텔 옵테인 SSD와 QLC NAND SSD의 결합은 가장 빈번하게 사용되는 데이터에 대한 접근 지연이 더욱 낮아지게 된다. 함께 이용할 경우, 이 플랫폼 및 메모리 발전 기술은 시스템 및 애플리케이션에 부합하는 올바른 선택권을 제공하는 메모리 및 스토리지 구조를 완성시킨다.
딥 러닝 레퍼런스 스택: 인텔은 인텔® 제온® 스케일러블 플랫폼에 최적화된 통합, 고성능 오픈 소스 스택인 딥 러닝 레퍼런스 스택(Deep Learning Reference Stack)을 공개한다. 이러한 오픈 소스 커뮤니티 공개는 AI 개발자들이 인텔 플랫폼의 모든 기능에 쉽게 접근할 수 있도록 보장하기 위한 노력의 일환이다. 딥 러닝 레퍼런스 스택은 클라우드 네이티브 환경을 위해 고도의 튜닝 및 개발 과정을 거쳤다. 이번 공개를 통해, 인텔은 여러 개의 소프트웨어 요소를 통합하는 데에서 발생하는 복잡함을 줄여 개발자들이 빠르게 프로토타입을 개발하고, 사용자에게는 자신의 솔루션을 맞춤 구성할 수 있는 유연성을 제공한다.
- 운영체제: 클리어 리눅스*(Clear Linux*) OS – 개별적인 개발 필요에 맞게 맞춤 구성이 가능하며, 인텔 플랫폼 및 딥 러닝과 같은 특정 활용사례에 맞도록 조정
- 오케스트레이션: 큐버네티스*(Kubernetes*) – 인텔 플랫폼을 인식하는 다중 노드 클러스터를 위해 컨테이너화된 애플리케이션을 관리 및 오케스트레이션
- 컨테이너: 도커* 컨테이너(Docker* Containers) 및 카타* 컨테이너(Kata* Containers) – 인텔® 가상화 기술 (Intel® Virtualization Technology)을 활용해 컨테이너의 보안 지원
- 라이브러리: 딥 뉴럴 네트워크용 인텔® 매스 커널 라이브러리(Intel® Math Kernel Library for Deep Neural Networks, MKL DNN) – 수학적 기능 퍼포먼스에 최적화된 인텔의 매스 라이브러리
- 런타임: 파이선*(Python*) – 인텔 아키텍처에 맞게 고도의 튜닝 및 최적화를 거친 애플리케이션 및 서비스 실행 런타임 지원
- 프레임워크: 텐서플로*(TensorFlow*) – 첨단 딥 러닝 및 머신 러닝 프레임워크
- 구현: 쿠브플로우*(KubeFlow*) – 오픈 소스 형식의 업계 주도형 구현 툴로 인텔 아키텍처에서의 빠른 경험, 설치 편의성을 제공하며 한번 설치하면 간단하게 사용 가능







 |







 |

[인터뷰] 최원혁 인텔코리아 상무 / 인텔 Ultra, AI PC 시대 열었다
조회수 338회 / intel
 인텔 선임 연구과학자.jpg)
코가 없는 컴퓨터 칩이 냄새를 맡는 방법
조회수 14278회 / Intel

양자 확장성을 구현하는 인텔 "호스 리지"
조회수 1361회 / Intel

인텔, 엣지 AI 시장 개화를 앞당긴다 :
‘엣지 AI 포럼’을 통해 차별...
조회수 1457회 / Intel

Intel, 양자컴퓨터 실용화를 향한 여정은 이제부터 시작
조회수 1139회 / 인텔

양자 컴퓨팅 상용화로의 경주는 마라톤이다
조회수 1130회 / Intel

컴퓨팅의 다음 세대를 견인할 혁신적인 5가지 인텔 플랫폼
조회수 1659회 / Intel
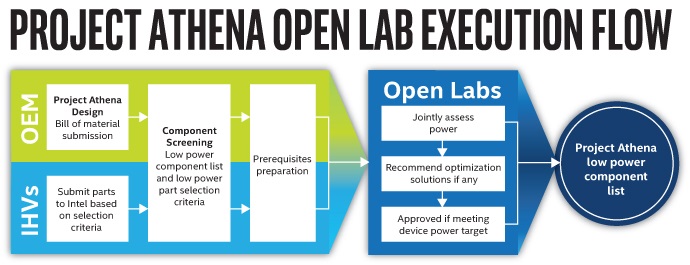
인텔, 노트북 부품 최적화를 위한 생태계 통합 확장하는 아테나 프로젝...
조회수 1854회 / Intel

인텔, 새로운 인텔® v프로™ 플랫폼 발표로 모바일 중심 시대 IT 및 직원...
조회수 2392회 / Stephanie Hallford
PDF 다운로드
 |
회원 정보 수정
